About the project
A cross-city investigation of how generative AI interprets and visualizes "sustainable" urban streetscapes.
Motivation
A sustainable streetscape is commonly associated with greenery, improved pedestrian infrastructure, cycling facilities, and traffic calming — yet the concept itself remains ambiguous and contested. What counts as "sustainable" is deeply contingent on local urban morphology, governance priorities, and socio-cultural expectations. A streetscape considered sustainable in one context may be inappropriate or counterproductive in another.
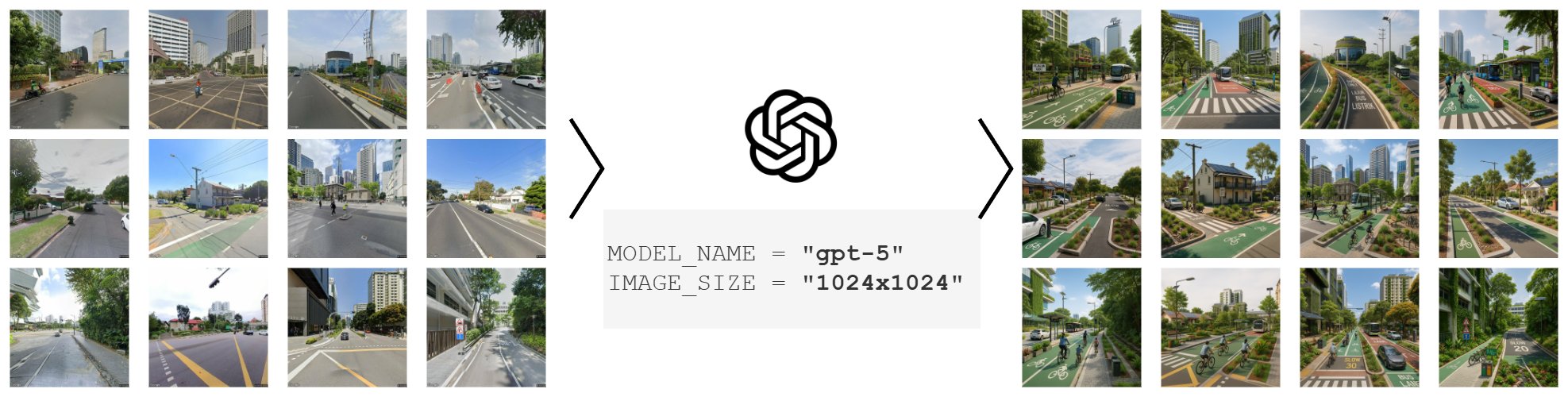
Generative AI tools are now entering the workflows of architects, urban planners, and policy communicators. They can translate text prompts into vivid streetscape visualizations, scaling design ideation in ways previously impossible. But this comes with a risk: when sustainability is applied through generalized transformation rules, it can be reduced to a limited set of recurring features — vegetation, bike lanes, widened sidewalks — replicated across cities regardless of fit. Sustainability may quietly become a standardized aesthetic rather than a place-based strategy.
This project asks: do AI-generated outputs reflect context-sensitive improvements, or do they unintentionally standardize what "sustainable" streetscapes should look like across different urban settings?
Research questions
- What general visual characteristics are associated with AI-generated sustainable streetscapes?
- How does the semantic composition of streetscapes shift during transformation toward becoming "more sustainable"?
- To what extent do these transformations lead to homogenization of streetscape semantics and a reduction of cross-city variation?
- How does prompt specificity (context-rich vs. generic) shape what generative AI produces under the label "sustainable"?
Methodology
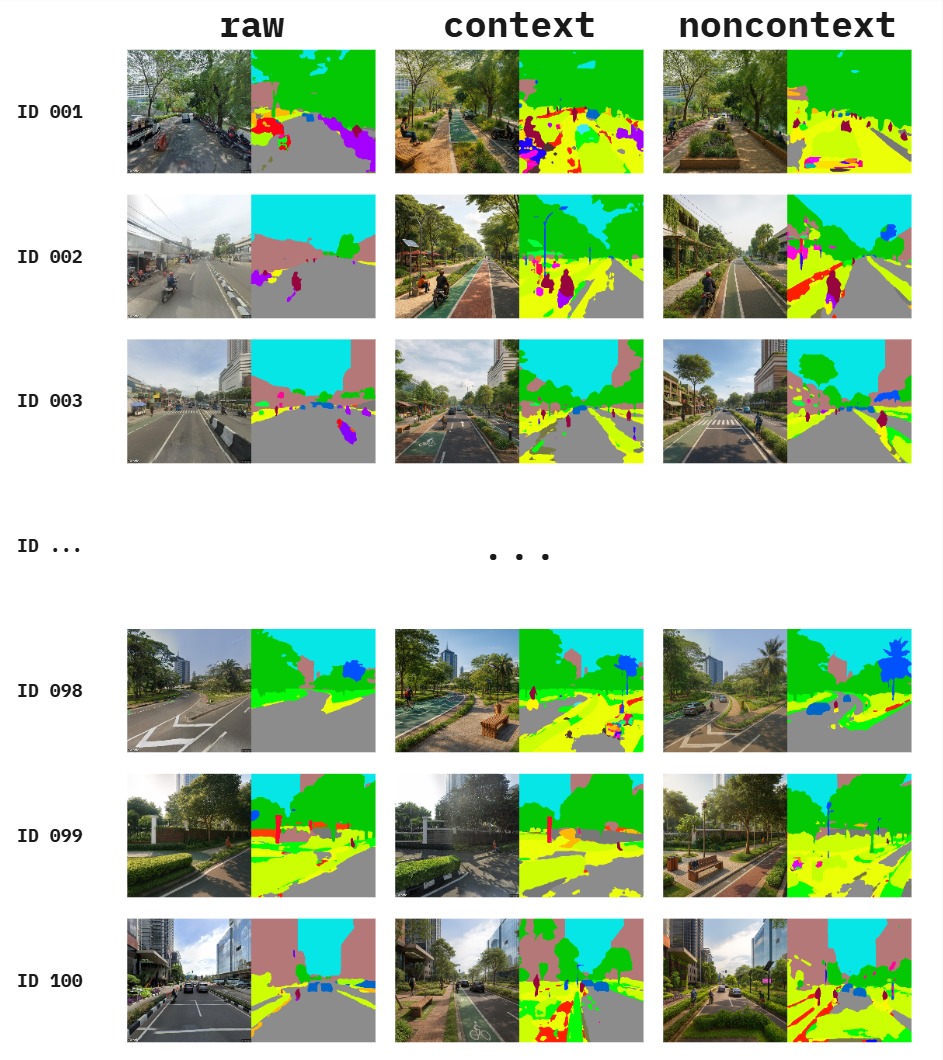
The project combines three methodological pillars: street-view imagery collection from selected cities (Jakarta, Melbourne, Singapore), controlled image-to-image transformation using OpenAI multimodal models (GPT-4o, GPT-5), and semantic analysis of the outputs through pre-trained segmentation models (Mask2Former with Swin-Large backbone, trained on ADE20K).
Pixel-level segmentation outputs are aggregated into seven domain-relevant categories (sky, vegetation, built structure, road infrastructure, vehicle, water and natural, street furniture) and projected into a shared two-dimensional space using UMAP. Scene typologies are identified through K-Means clustering on the raw images, then projected onto the AI-generated images as a fixed baseline. This design choice — clustering on raw images only — ensures that any redistribution of AI images across clusters reflects a genuine structural shift, not a contamination of the reference geometry.
Homogenization is assessed using four complementary metrics: mean pairwise distance, normalized cluster entropy, feature diversity, and convex hull area. Cross-city distinguishability is tested using chi-square independence tests with Cramér's V.

Key findings (so far)
- Vegetation inflation in every cluster and city, with road and sky area reciprocally compressed.
- Within-city compositional convergence: feature diversity declines 23%–31% across the three cities studied.
- Between-city distinguishability is preserved — Jakarta, Melbourne, and Singapore remain statistically separable after transformation.
- Prompt specificity matters: context-rich prompts produce more balanced streetscapes (with sidewalks, stormwater features, public seating, lighting), while generic prompts default to culturally salient "sustainability markers" — cycle lanes and manicured greenery.

.jpg)